Spec-Hub: A Team Harness for Spec-Driven, AI-Native Development
Plan on Claude Code, execute on Codex, hand off without losing context. The tracker is the contract.

TL;DR: Specs are the new source code. Managing them at team scale is its own engineering problem. I built spec-hub, a stateless MCP service backed by MongoDB that gives any team a shared harness for feature capsules, sessions, handoffs, and knowledge. It works with any MCP-aware client (Claude Code, Codex, Cursor) without taking away any of the per-repo conventions, hooks, or slash commands developers already rely on.
Specification Is the New Source Code
Coding agents can already implement most of what you ask them for. That isn't the bottleneck. The bottleneck is deciding what to build, knowing what's already done, tracking who owns what across repos, and not letting context evaporate between sessions. If a team can't answer those questions reliably, the agent doesn't close the gap; it just types faster against it.
Specs are the new source code. The PRD, the tracker, the design notes, the dependency graph, and the list of "what we learned the hard way last quarter" used to be documentation around the work. Now they are the work, or at least the high-leverage part of it. The agent does the typing. The human writes the spec the agent types from.
Managing those specs at team scale is an engineering problem with the same characteristics as any other system, including state, concurrency, versioning, and access control. It scales badly if you ignore it. This post is about the system I built to address that.
Key idea: When the agent writes most of the code, the team's leverage point is the spec. Manage it like infrastructure.
The previous posts each picked one human role (the PM in issue-builder, the designer in ui-orchestrator) and built a harness that brought them into the AI loop where their judgment mattered. This post is about the harness for the team itself.
Why This Matters in Practice
If you've worked in an AI-assisted codebase for more than a few weeks, you've felt the failure modes:
The same questions get answered differently every session. Which file owns the persona model? Where does session state live? The agent re-discovers the answer each time, sometimes correctly, sometimes not.
Plans evaporate. Claude Code writes a multi-phase plan to
~/.claude/plans/, the developer closes the terminal, and the plan now lives on exactly one laptop.Knowledge dies with whoever wrote it down. The reason we don't mock the database in integration tests, the reason the migration runs at 3am. It walks out the door when that developer does.
Two developers (or two AI agents) edit the same area unaware of each other.
Multi-repo state has nowhere to live. Linear has tickets, Notion has docs, repos have CLAUDE.md files, but nothing knows which feature owns which write paths across which repos.
These are coordination problems, not AI problems. Better models won't fix them. Better orchestration will.
Spec-Hub: A Harness, Not Another Tool
Spec-hub is a stateless MCP server backed by MongoDB. It exposes about 25 specHub_* tools any MCP-capable client can call. The unit it operates on is the feature capsule, a bundle holding the PRD, tracker, plan, design notes, dependency notes, and a small knowledge base, all keyed to one feature inside one service. The coordination is layered. The tracker holds real-time per-story status anyone on the team can read at any time; sessions and handoffs add richer context when the tracker's granularity isn't enough.
It is intentionally not a coding agent. It does not edit files, generate UI, or write tests. It tells whichever agent you are using what to work on, what's already done, what the constraints are, and where to write the result back. The editor stays yours.
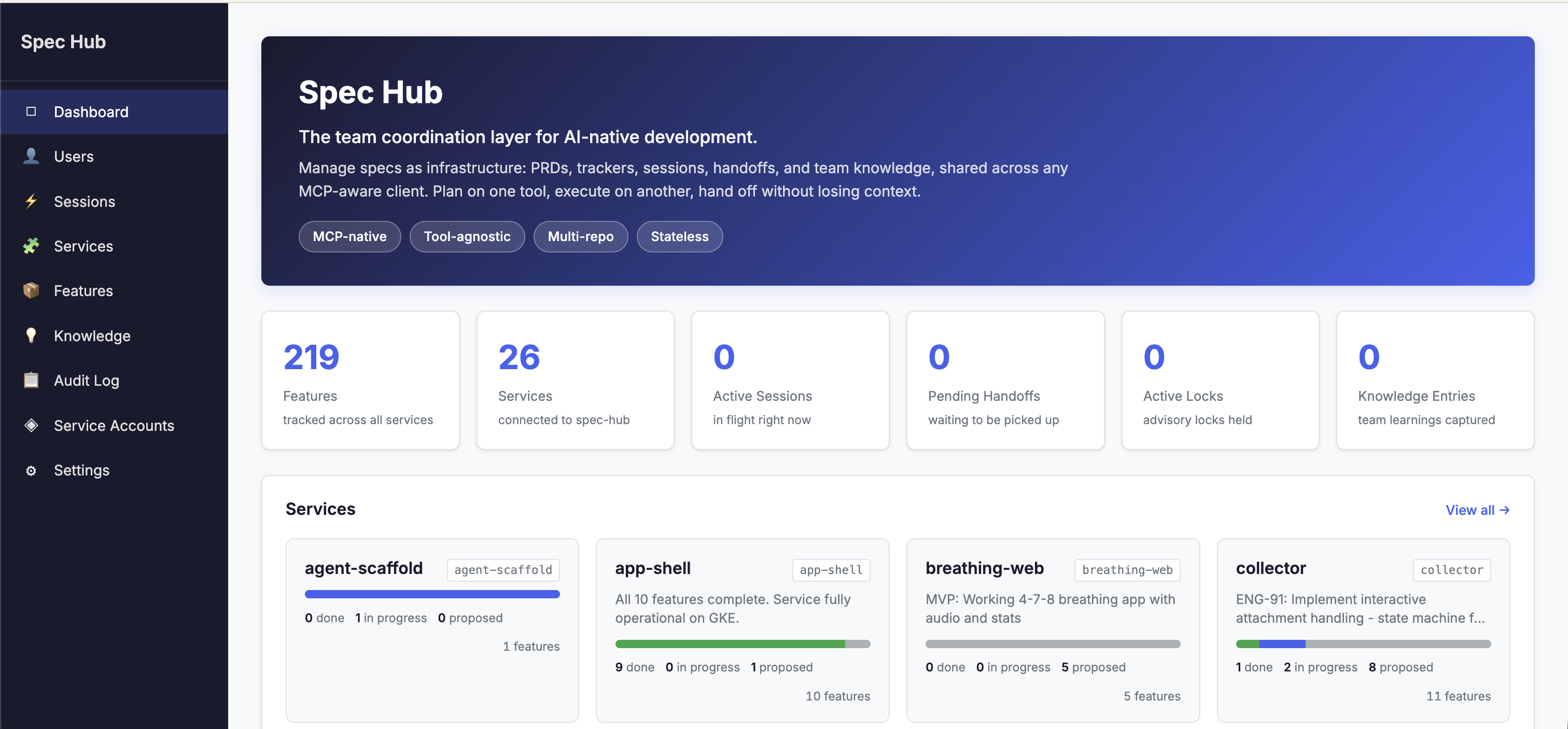
The spec-hub landing page, with feature counts by service, active sessions, advisory locks, and recent activity. Most days you'll spend more time inside Claude Code than this dashboard, but the dashboard is where humans on the team check in on what their AI agents have been doing.
Two design choices anchor everything else.
Spec-hub is agnostic about your client. Any tool that speaks MCP (Claude Code, Codex, Cursor, whatever ships next quarter) can connect via GitHub OAuth and call every tool the harness exposes. Tools change; the harness shouldn't.
Spec-hub does not take away the tools you already use inside your repos. Per-repo CLAUDE.md, AGENTS.md, hooks, slash commands, MCP allowlists, and sub-agent definitions all stay untouched. The bootstrap-generated workspace CLAUDE.md lives one directory above your repos rather than inside any of them, with no overlap into how your codebase is organized.
Key idea: A harness should add structure at the team layer without colonizing the developer's local one.
In practice, spec-hub gives a team:
A shared feature-level source of truth (PRD plus tracker), queryable from any MCP client.
Tool-agnostic pickup, so any agent that speaks MCP can read where work left off.
Persistent memory across sessions, developers, and tools, backed by MongoDB rather than one developer's laptop.
Structured handoffs that route through Linear, so the receiver gets a ticket with the continuation prompt and file:line cursor attached.
Multi-repo visibility through write roots and dependency graphs that prevent scope creep when an agent edits across services.
A workspace-level
CLAUDE.mdthat teaches the client when to call which tool, without touching any per-repo conventions.
From Single-Tool Harness to SaaS
Spec-hub started life as a single-tool harness, useful to me on my own machine but invisible to anyone else on the team or anyone running a different client. Converting it into an MCP-exposed SaaS service was the move that made it shareable. The discovery scoring, the mandated reading order, the handoff protocol, the compaction logic. All of it moves server-side, and the client becomes anything that speaks MCP.
Architecture
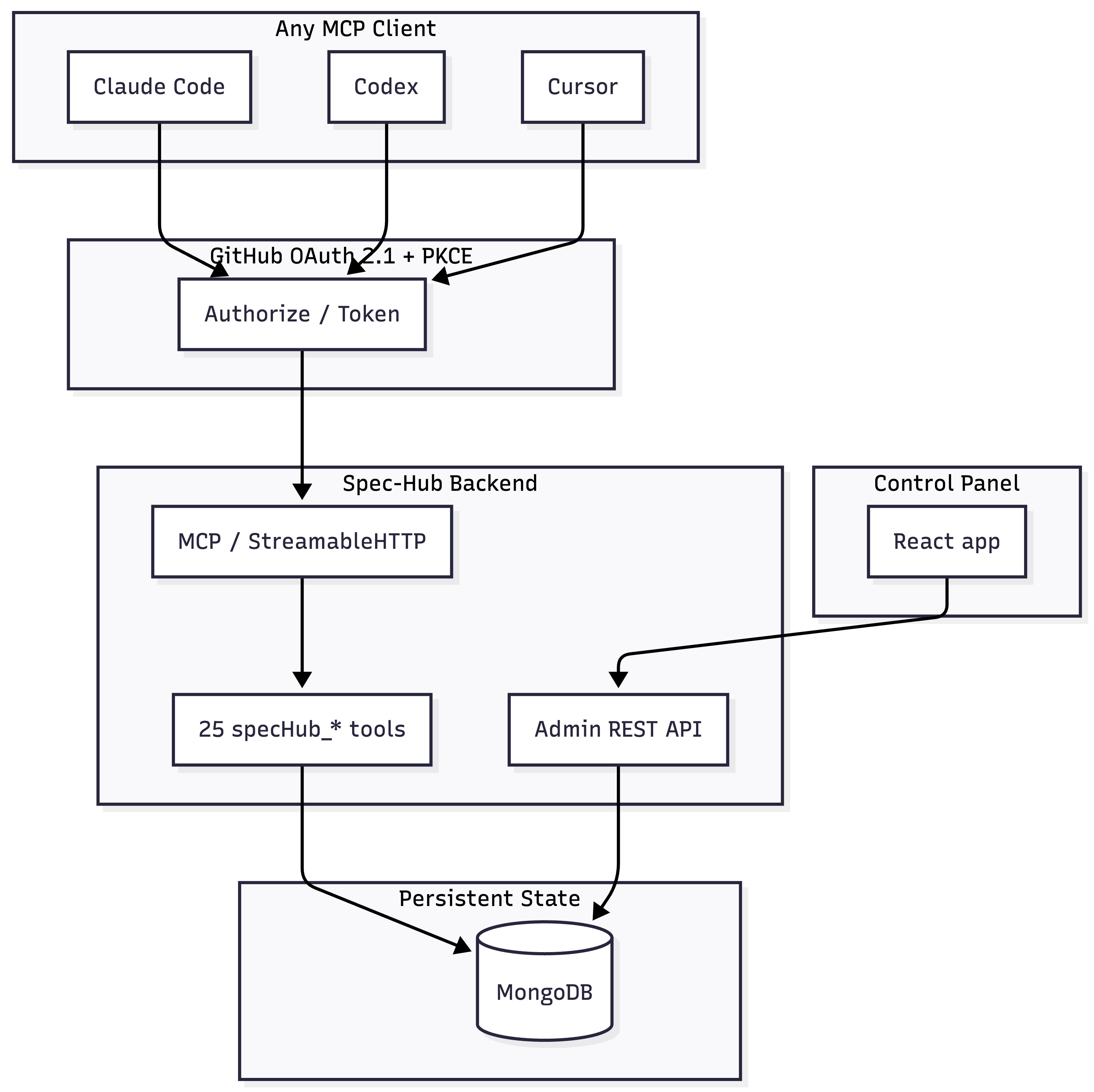
Any MCP-aware client authenticates through GitHub OAuth, then calls one of 25 tools that read or write feature state in MongoDB. The dashboard reads the same MongoDB through a separate REST API. There is no server-side session affinity anywhere.
Two things on the diagram are load-bearing.
Stateless tools. State lives in MongoDB, not in a server process, so picking up a handoff from a different machine, a different tool, or a different developer is the same operation.
OAuth-only by default. Authentication is GitHub-delegated through the standard MCP OAuth flow, the same pattern Linear uses for mcp.linear.app/mcp. There is no user-facing API key. claude mcp add --transport http spec-hub https://... opens a browser, the user approves, and the client stores the token. Admins add new developers from a dashboard that lists GitHub org members; that single action is the entire onboarding ritual.
How Work Gets Picked Up
There are three layers to "where did the last session leave off?", from default to deliberate.
The tracker is the default. Every story has a status (todo / in_progress / done) and a file path. Anyone on the team can open the dashboard or call specHub_loadFeatureContext and see, in real time, exactly what's been completed and what's next. If a developer disappears mid-feature (vacation, illness, just moving on to something else), another developer can pick up using the tracker alone. They read the PRD, read the tracker's current state, and continue. No handshake required.
In practice this is how I pick up most work, including my own. The tracker is always on. It's the coordination layer that runs without anyone having to do anything special.
Sessions are optional and mostly for self-continuity. When a developer is in the middle of something (three files open, a half-applied refactor, a cursor at a file:line where context just filled up), the tracker doesn't capture that depth. specHub_saveSession snapshots the in-progress task, the active files, the next steps, and a continuation prompt that boots the next session more precisely than the tracker alone would. The next morning, same developer, same tool, specHub_getContinuation puts them back where they were.
If your work happens in clean story boundaries (finish a story, mark it done, walk away), sessions don't add much over the tracker. I use them when the work is messier than that, which isn't every day.
Handoffs are deliberate, and they generate a Linear ticket. A handoff is what you do when context is rich enough that you want to route it to a named person through their normal workflow. specHub_createHandoff snapshots the same continuation state a session would, marks the original session handed_off, releases the lock, and creates a Linear ticket assigned to the receiver, with the continuation prompt, the file:line cursor, the current-thinking notes, and a link back to the feature capsule attached. The receiver gets the ticket in their Linear inbox the way they get every other one, opens it, and runs specHub_pickupHandoff from whichever tool they're on.
The tracker alone would have been enough for them to technically take over. The handoff exists because in real teams the routing matters. A notification, a name, a Linear thread to comment on, a record that the work changed hands. Common cases are end-of-quarter rollovers, vacation handoffs, and the one I hit most. It's 4pm, I've burned my Claude Code budget, I open a handoff to myself; the next morning I pick it up on Codex from the Linear ticket. Same feature, same file:line, different tool.
In day-to-day use, I lean on the tracker. Sessions and handoffs are escalations for the cases where per-story granularity isn't enough.
Key idea: The tracker is always on. Sessions add richer self-resume context; handoffs add deliberate routing through a Linear ticket. Use the smallest layer that fits.
Implicit Handoff: Plan on One Tool, Execute on Another
Here's the pattern in practice. The setup is a small feature for spec-hub itself, a Raw / Preview toggle on the feature document viewer so PRDs, plans, and notes render as formatted markdown rather than as a wall of text. Phase 1 (planning) gets done on Claude Code. Phase 2 (execution) gets done on Codex. No specHub_createHandoff call in between, no specHub_saveSession, no Linear ticket. Just the tracker.

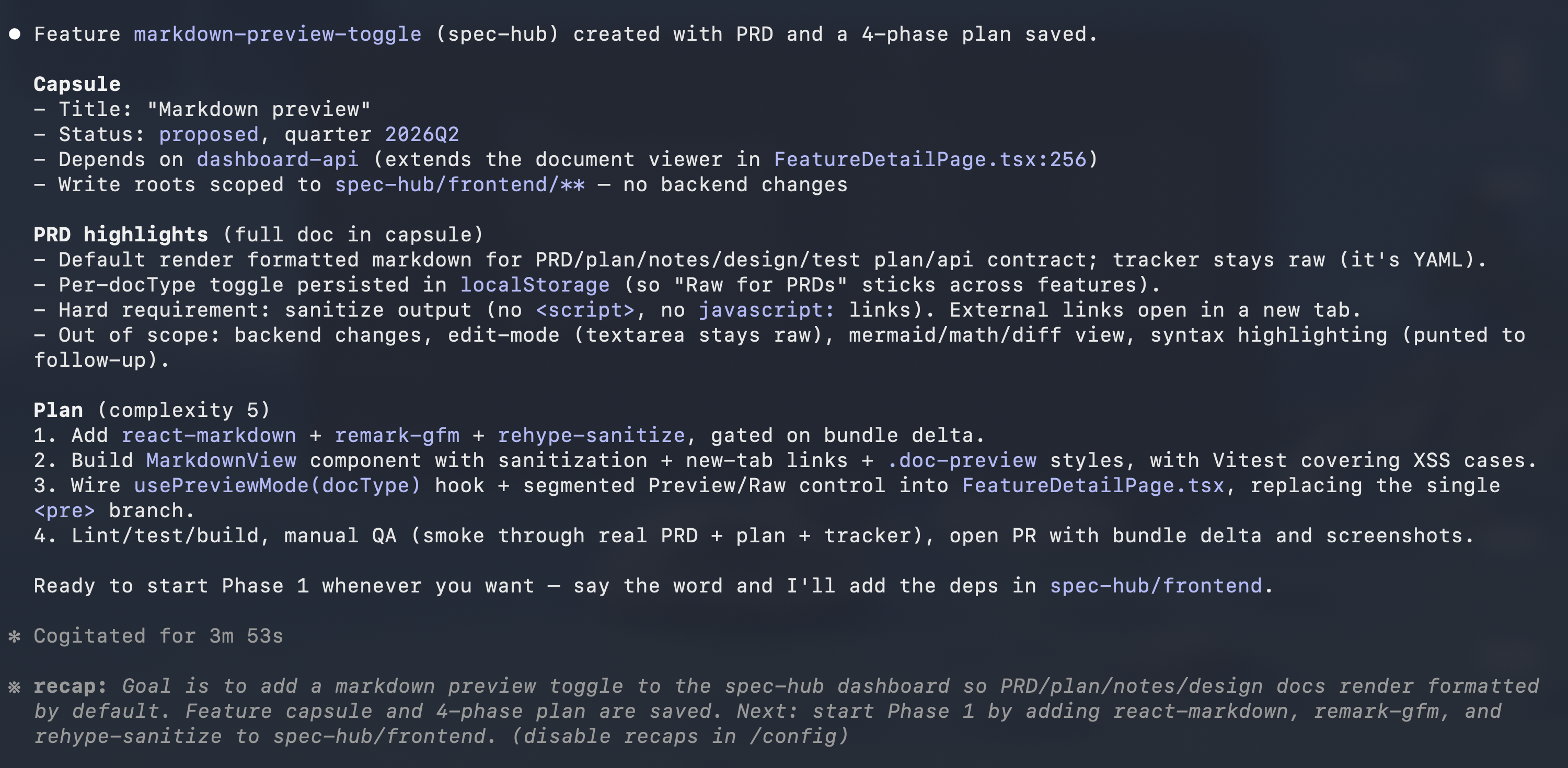
Claude Code reads the existing feature document, drafts a plan, and creates the
markdown-preview-togglefeature in spec-hub with six stories mapped to real file paths. The session ends without any handoff ceremony, just a closed terminal.
A little while later, in a fresh Codex session in the same workspace:
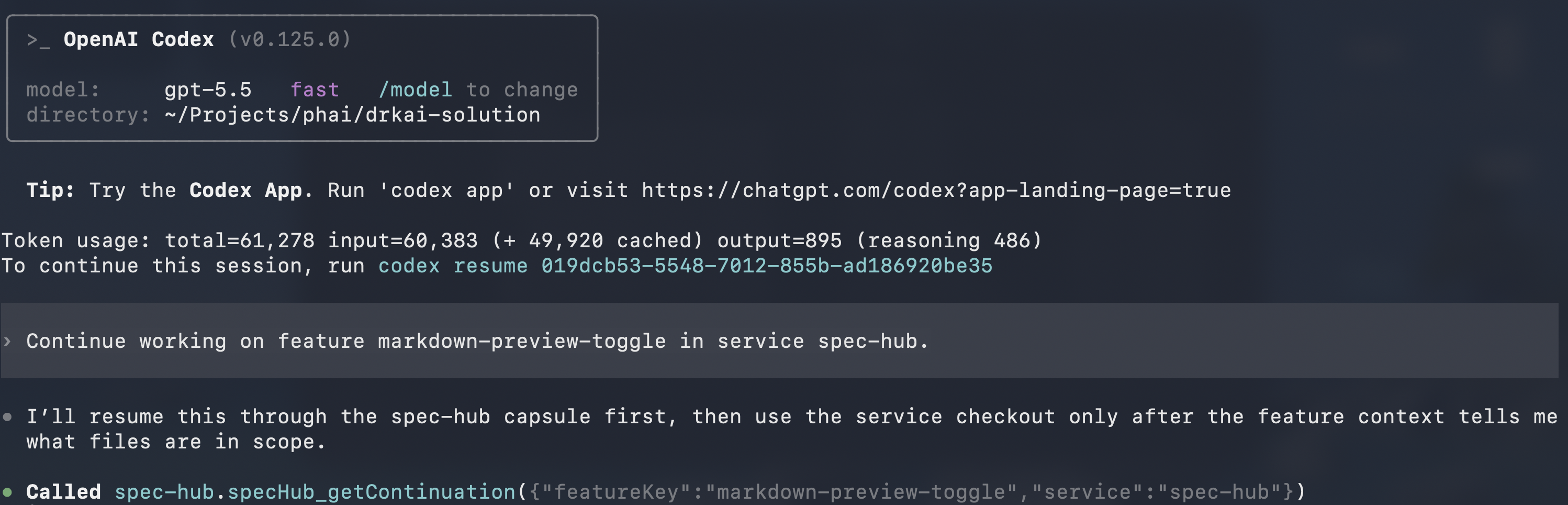
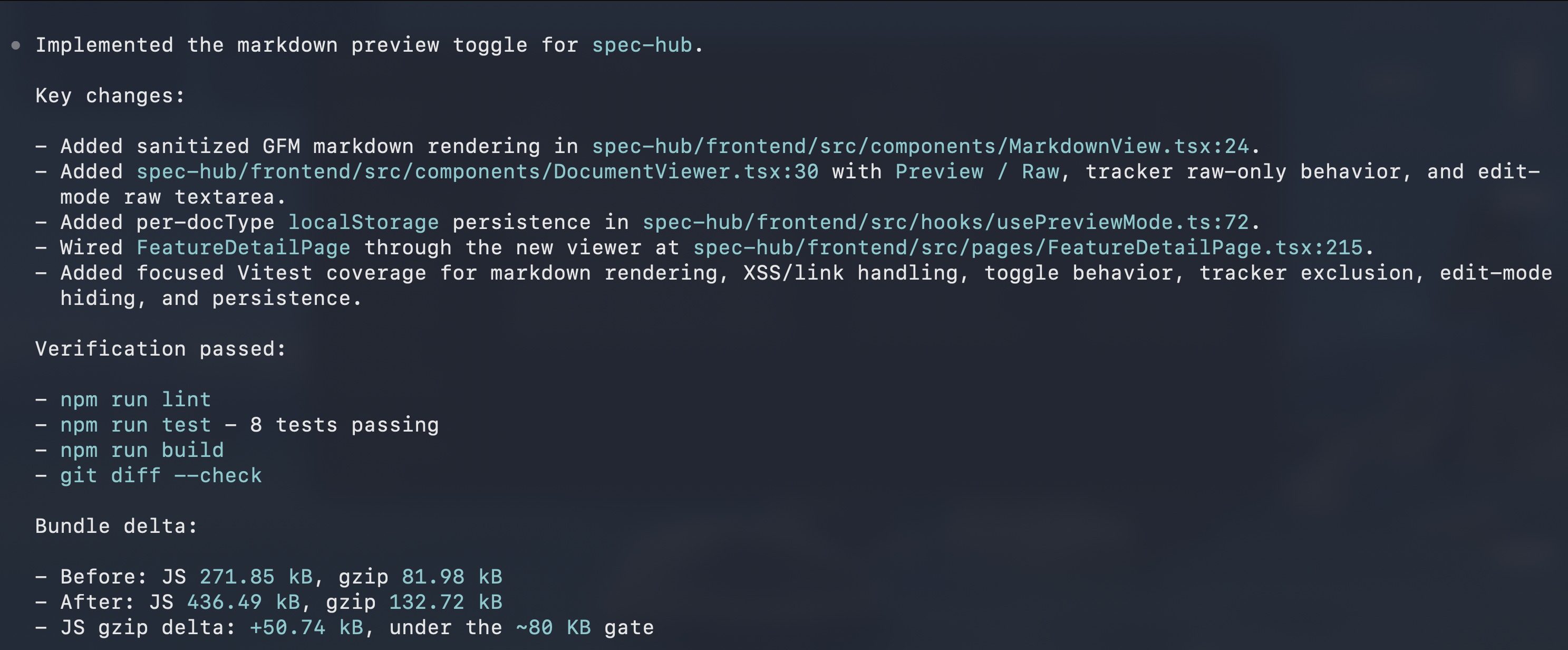
Codex calls
specHub_loadFeatureContextfor the same feature and receives the PRD, the tracker, and the next pending story exactly as Claude Code left them. Nothing was passed by hand.
As Codex works through the stories, each specHub_updateTracker call moves a story to done. The dashboard reflects each transition in real time. Any developer or tool on the team could read the same state at any of those moments.
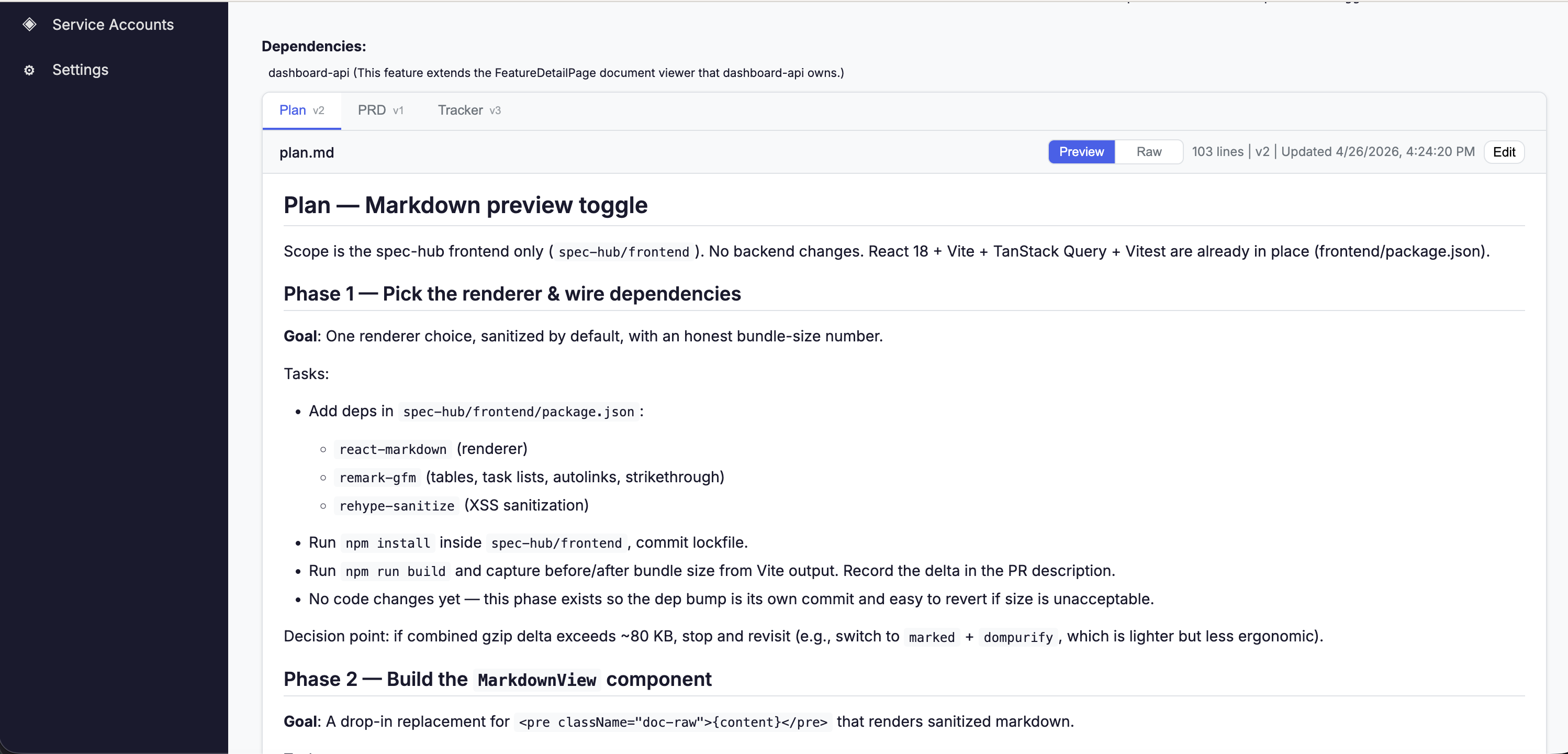
The completed feature as planned by Claude Code and implemented by Codex.
The point isn't that one tool did the planning and another the execution. The point is that nothing extra had to happen for that to work. The tracker is the contract. Whichever client speaks MCP can read it, advance it, and hand off implicitly to whoever (or whatever) reads it next.
Key idea: Implicit handoff is the everyday case. The tracker is the protocol; the editor is interchangeable.
The Tracker and PRD: An End-to-End Delivery Ledger
The tracker already showed up in the previous section as the always-on coordination layer. Up close, it's one of two documents that define a feature, and the pair is what closes the loop between "what we said we'd build" and "what we actually built."
The PRD is the goal. Acceptance criteria, user stories, technical approach. It changes slowly; when it does, changes go through notes/prd-changes-summary.md rather than an in-place rewrite, so the history of why a requirement evolved survives.
The tracker is the execution ledger. Phases, stories, statuses, file mappings. Updated through specHub_updateTracker, not by hand-editing YAML, so the same operation works from any tool. Stories carry pointers to the real files they touched.
specHub_verifyFeature closes the loop. It reads the PRD's acceptance criteria, reads the tracker's phase and story status, and reports the gap. If you can answer "is this feature actually done?" with a tool call instead of a Slack thread, you have an end-to-end ledger.
Multi-Repo: Write Roots and Dependencies
Most teams aren't a monorepo. Spec-hub assumes a parent workspace directory containing several service checkouts side-by-side. Features can live in any of them; some touch more than one.
Write roots scope a feature's blast radius. Each feature carries glob patterns (for example, ../drkai/backend/src/**) that say where it's allowed to write. specHub_checkWriteRoot is advisory. It warns when a path is out of scope; it doesn't block. The point is to make scope creep visible at the moment it happens, not to police writes.
Cross-feature dependencies are declared up front. If feature A's work would require changing feature B, the convention is "document the change you'd want in notes/dependency-changes.md on A; do not edit B silently." specHub_analyzeDeps walks the graph in both directions.
This matters more with AI doing the typing. A coding agent will happily edit anything in its context. Without write roots and dep analysis, "implement the billing change" can quietly turn into 47 edits across 4 repos. With them, the agent has the means to stay in the right repo and surface the cross-repo edits it would have made as questions instead of commits, provided it calls these tools. Wire specHub_checkWriteRoot into a post-write hook to make the check fire on every save; otherwise it runs when the agent or the user asks.
The Bootstrap Move: Top-Level CLAUDE.md, Per-Repo Freedom
specHub_bootstrapWorkspace returns a versioned, canonical CLAUDE.md and instructs the client to write it to the current working directory, which by convention is the multi-repo parent containing your service checkouts. Not inside any service repo. The level above.
That file teaches the client when to call which specHub_* tool. It's a routing table. "User says 'continue feature X' → call specHub_getContinuation then specHub_loadFeatureContext. User says 'what's left for service Y' → call specHub_whatsNext. User reports a bug → call specHub_discoverFeatures first, before any code reading." It says nothing about how your code is organized, how to run your tests, or which framework you're on. None of that is its business.
The consequence is two clean layers:
The two layers don't overlap and they don't compete. A developer who has spent six months tuning the perfect set of hooks, slash commands, and sub-agents for their backend repo loses none of that by adopting spec-hub. The workspace CLAUDE.md lives at the directory you launch claude from; per-repo CLAUDE.md files load as the agent reads files inside each service. The two complement each other. The workspace prompt routes user intent to spec-hub tools, and per-repo prompts shape how the agent edits code once it's inside a service.
One detail is worth being explicit about. Spec-hub's flow assumes you launch claude from the multi-repo parent directory. Launching from inside a single repo skips the workspace layer, which is fine for solo per-repo work but bypasses the team-coordination flow that makes spec-hub valuable.
Key idea: The workspace prompt teaches MCP discipline at the orchestration layer. Per-repo
CLAUDE.md, hooks, slash commands, and tool allowlists keep owning the code layer. Two layers, no overlap.
"Can't You Just Use Claude Code Skills, Per-Repo CLAUDE.md, and Notion?"
Fair question. That combination genuinely works for a solo developer, even across multiple repos. Claude Code happily spans a workspace, per-repo CLAUDE.md keeps conventions where they belong, and writing trackers and notes by hand goes a long way.
The seams show with a team. A second developer joins and needs the skills installed, the helpers copied, the conventions explained. Switching tools means the client-specific skills don't apply. A plan written today lives in ~/.claude/plans/ on one laptop and is gone tomorrow. Across multiple repos, "what's the state of feature X" is hard to answer reliably.
These are the kinds of problems CI/CD pipelines exist to solve in the deployment world, not because deploying manually is impossible, but because manual processes don't survive contact with a team. Spec-hub didn't replace Claude Code or Cursor or Codex; it gave them a shared structure to operate within.
Even solo, on a single repo, the structured PRD and tracker keep context from leaking between sessions, the knowledge base catches gotchas before they're forgotten, and specHub_verifyFeature closes the loop on "is this actually done?". The team-coordination features are where the multiplier kicks in once a second person joins, a second tool gets adopted, or a second repo enters scope.
Closing Thoughts
If there's one sentence that captures the design philosophy, it's this. The team layer lives on the server; the developer layer stays local. The bottleneck on AI-native engineering teams is moving from generation to coordination. Whether the work the model just did connects cleanly to the next thing, whether the team knows it happened, whether it's verifiable against the spec, whether it survives the developer's laptop being closed. None of that is a model-quality problem.
This is one approach to a problem that other teams will solve other ways. Some will land on Linear plus discipline. Some will write a custom MCP server tailored to their stack. Some will find that GitHub Spec Kit plus a shared Notion is enough, and they'll be right for their size. The architecture matters less than the recognition. Managing the spec at team scale is its own engineering problem now, not a side effect of doing the work.
The teams that figure this out first won't be the ones with the best AI or the best PMs or the best designers. They'll be the ones who put all of them in the same loop without forcing any of them to give up the tools they're already good with.
If you're feeling the same coordination pain, the question worth holding in your head is which layer is doing the routing, which layer is doing the editing, and what state is keeping them honest. I'd be curious to hear how others are answering that. If you're tackling it from a different angle, drop a note.



